AI Agent RAG Basics
一般情况下,LLM所掌握的是通用的知识,而在特定领域(如法律条文、企业员工手册等)上的理解往往较为有限。
为了解决这一问题,可以采用有监督微调(SFT,Supervised Fine-Tuning),即将这些专业知识内化到模型中。然而,微调不仅消耗大量 GPU 资源,还需要精心构建高质量数据集,并且最终效果难以保证。
相比之下,一种更高效的方法是挂载知识库,即在用户输入的基础上增加额外的上下文信息(Context),让 LLM 从中��获取相关知识。这种方式被称为 RAG(Retrieval-Augmented Generation,检索增强生成)。
目前,许多大模型的联网搜索、Perplexity搜索,以及知乎、小红书等平台的搜索增强与摘要功能,均基于 RAG 实现。
RAG组件
- 知识库:相关文本、语音等数据,为用户查询提供上下文支持。
- Embedding模型:将用户输入及知识库内容转换为向量,以便进行相似度匹配。
- 向量数据库:存储知识库内容的向量表示,并根据查询计算相似度,检索相关内容。
- LLM:结合用户输入和检索到的内容,生成最终的回答。
RAG流程
RAG主要分为以下三步步骤
-
输入处理(Input Transformation)
- 解析用户输入,提取关键词或关键信息,以便进行检索。
- 如果采用向量数据库匹配的方法,这里还需要对用户输入进行embedding向量化。
-
检索(Retrieval):
- 在数据源(如向量数据库、关系型数据库)中,检索与用户查询相关的信息。
- 对检索结果进行去重、排序(Rerank)等处理,以确保信息质量。
- 若采用向量匹配检索,则需对知识库内容预先进行 embedding 处理,并存储在向量数据库中。
-
生成(Generation):
- 将检索到的数据作为上下文(Context),与用户输入组装成 Prompt,请求LLM生成最终内容。
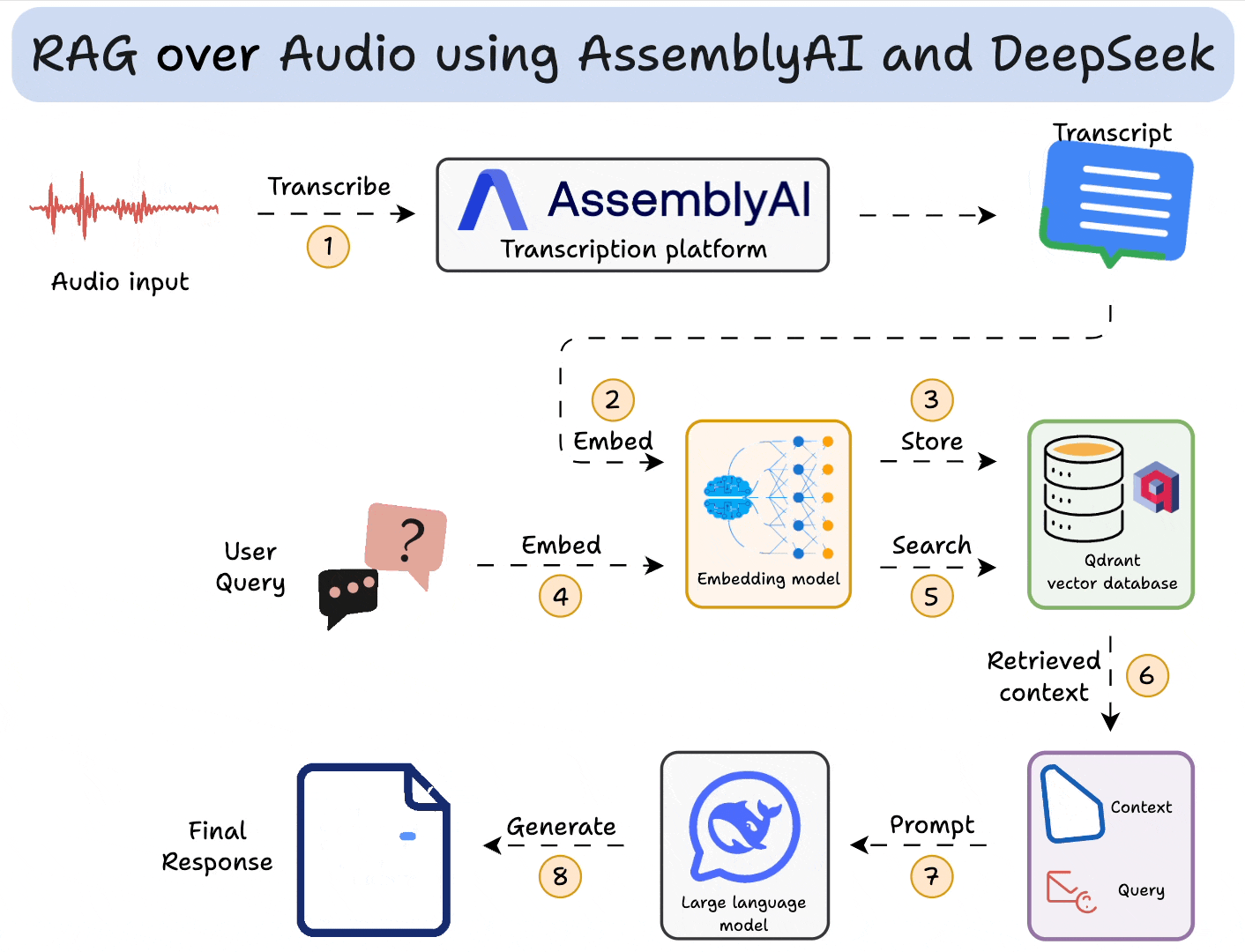
RAG 主要挑战
- 上下文过长。LLM 存在注意力衰减问题(Lost in the Middle Problem),即更关注输入的开头和结尾,对中间部分的关注度较低。因此,需确保输入的内容高度相关,而非简单堆砌大量信息。
- 内容冲突。从多个数据源检索内容时,可能会出现信息冲突(例如,不同数据源对同一概念的定义不同)。应严格筛选数据源,确保可靠性,以减少模型幻觉,减少模型幻觉(Hallucination)。
- 重复。可能会检索到重复信息,应采用去重技术(如 Maximal Marginal Relevance,MMR),以确保提供的信息多样性。
- 内容不相关。需要设置合适的相关度阈值(threshold),避免检索到无关数据,影响生成质量。
重新计算Embedding的情况
以下情况需要重新计算向量。
- 更换embedding模型
- 调整chunk大小
- 修改chunk结构,例如增加或移除某个字段。
- 为数据文件新增或修改元数据(Metadata)。
检索
一般有如下几种检索方式
- 语义检索 Semantics Search
- 当用户输入是自然语言且很长时,语义搜索可以理解用�户输入整体意图而不仅仅局限于某个关键词的重要性。
- 原理
- 使用embedding模型生成数据的向量,比如Vertex AI的
textembedding-gecko模型。 - 一般使用KNN来识别相关的数据向量。
- 而数据之间的相似度可以通过
- Cosine Similarity(余弦相似度),仅关注向量的方向
- L2 Distance(Ecludiean Distance,欧氏距离),同时考虑向量的方向和大小。
- 使用embedding模型生成数据的向量,比如Vertex AI的
- 实现:
- 向量数据库(如 Elasticsearch、PostgreSQL + 向量插件)。
- 索引:大规模数据检索时,需使用索引(如 HNSW,Hierarchical Navigable Small World)。
- 关键词搜索
- 适用于精准查询(Exact Match),响应速度快。
- 例如,Elasticsearch使用BM25算法进行关键词匹配。
- 混合搜索
- 结合语义搜索和关键词搜索,兼顾广度与精度,提高检索效果。
- 代码搜索
- 通过抽象语法树(AST)解析代码结构,提高搜索精度。
- 可使用 Elasticsearch 提供的模糊搜索(Blob Search)。
- ID搜索 ID Search
- 适用于数据主键(Primary Key)查询,可直接获取目标对象信息。
- 知识图谱 Knowledge Graph
- 通过构建实体及关系网络,提供更具内部互联性(interconnected)、上下文相关度更高、更丰富的检索结果。
- 适用于推荐系统、复杂数据分析等对数据的洞察要求更高的场景。
评估 Evaluation
检索生成的质量评估至关重要,若仅依赖用户�反馈,可能会导致优化偏差,影响整体用户体验。因此,应构建标准化数据集进行全面评估。
使用LangChain实战
使用 Transformers 和 LangChain,选择在 Retrieval -> Chinese 中表现较好的编码模型进行演示,即 chuxin-llm/Chuxin-Embedding。
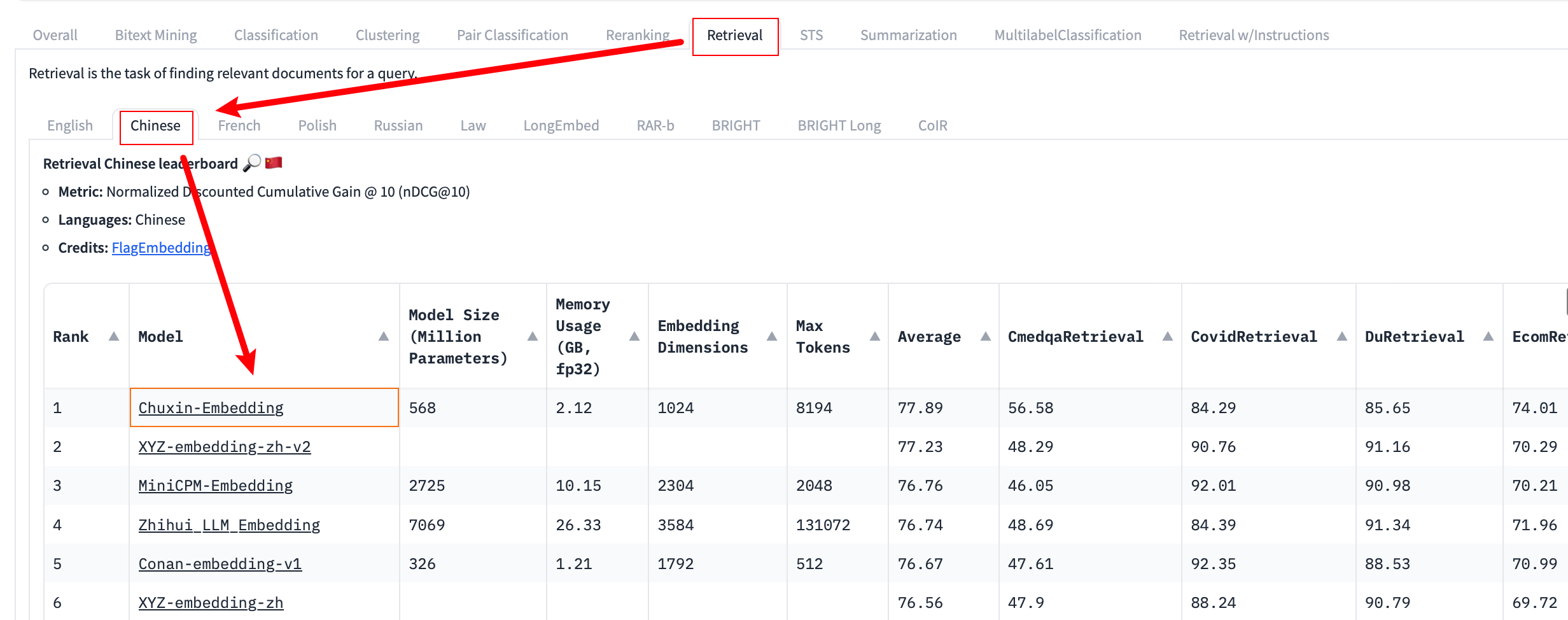
RA检索
在实际实现中,遵循的步骤大致如下:
- 使用预训练的编码器模型将「文档」内容编码为向量表示(embedding),然后建立一个向量数据库。
- 在检索阶段,针对用户的「问题」,同样使用编码器将其编码为向量,然后在向量数据库中寻找与之相似的文档片段。
文档导入
from langchain.document_loaders import DirectoryLoader
# 定义文件所在的路径
DOC_PATH = "../Guide"
# 使用 DirectoryLoader 从指定路径加载文件。"*.md" 表示加载所有 .md 格式的文件,这里仅导入文章 10(避免当前文章的演示内容对结果的影响)
loader = DirectoryLoader(DOC_PATH, glob="10*.md")
# 加载目录中的指定的 .md 文件并将其转换为文档对象列表
documents = loader.load()
# 打印查看加载的文档内容
print(documents[0].page_content[:200])
文本处理
LangChain 提供了多种文本分块方式,例如 RecursiveCharacterTextSplitter、HTMLSectionSplitter、MarkdownTextSplitter 等,可以根据需求选择。本文将演示 RecursiveCharacterTextSplitter。
在使用 split_documents() 处理文档之前,我们先使用 split_text() 来看看它究竟是怎么进行分块的。摘取一段长隆万圣节的文本介绍:
text = """长隆广州世界嘉年华系列活动的长隆欢乐世界潮牌玩圣节隆重登场,在揭幕的第一天就吸引了大批年轻人前往打卡。据悉,这是长隆欢乐世界重金引进来自欧洲的12种巨型花车重磅出巡,让人宛若进入五彩��缤纷的巨人国;全新的超级演艺广场每晚开启狂热的电音趴,将整个狂欢氛围推向高点。
记者在现场看到,明日之城、异次元界、南瓜欢乐小镇、暗黑城、魔域,五大风格迥异的“鬼”域在夜晚正式开启,全新重磅升级的十大“鬼”屋恭候着各位的到来,各式各样的“鬼”开始神出“鬼”没:明日之城中丧尸成群出行,寻找新鲜的“血肉”。异次元界异形生物游走,美丽冷艳之下暗藏危机。暗黑城亡灵出没,诅咒降临。魔域异“鬼”横行,上演“血腥恐怖”。南瓜欢乐小镇小丑当家,滑稽温馨带来欢笑。五大“鬼”域以灯光音效科技情景+氛围营造360°沉浸式异域次元界探险模式为前来狂欢的“鬼”友们献上“惊奇、恐怖、搞怪、欢乐”的玩圣体验。持续23天的长隆欢乐玩圣节将挑战游客的认知极限,让你大开眼界!
据介绍,今年长隆玩圣节与以往相比更为隆重,沉浸式场景营造惊悚氛围,两大新“鬼”王隆重登场,盛大的“鬼”王出巡仪式、数十种集声光乐和高科技于一体的街头表演、死亡巴士酷跑、南瓜欢乐小镇欢乐电音、暗黑城黑暗朋克、魔术舞台双煞魔舞、异形魔幻等一系列精彩节目无不让人拍手称奇、惊叹不止的“玩圣”盛宴让 “鬼”友们身临其境,过足“戏”瘾!
"""
print(len(text))
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 创建一个文本分割器。
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100, # 每个文本块的最大长度
chunk_overlap=20 # 文本块之间的字符重叠数量
)
# 将文本分割成多个块
texts = text_splitter.split_text(text)
# 打印分割后的文本块数量
print(len(texts))
# 打印第一个文本块的长度
print(len(texts[0]))
# 打印第一个文本块的最后 20 个字符
print(texts[0][80:])
# 打印第二个文本块的前 20 个字符
print(texts[1][:20])
这段文本长度为 581。chunking后输出为
9
100
出巡,让人宛若进入五彩缤纷的�巨人国;全新
出巡,让人宛若进入五彩缤纷的巨人国;全新
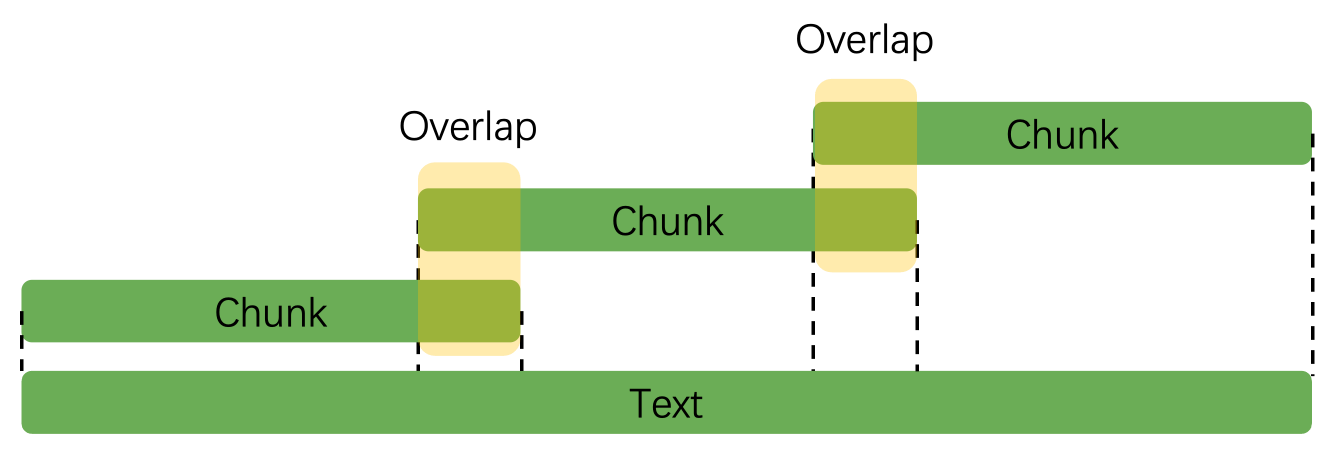
overlap
可以观察到第一个文本块的后20个字符和第二个文本块的前20个字符相同。第一段文本确实以 100 个字符进行分割,而且 overlap 符合预期。
实际上,RecursiveCharacterTextSplitter() 的关键在于 RecursiveCharacter,即递归地按照指定的分隔符(默认为 ["\n\n", "\n", " ", ""])进行文本拆分。也就是说,在文本拆分的时候,它会尝试使用较大的分隔符来拆分文本,如果长度仍超过 chunk_size,则逐步使用更小的分隔符,直到长度满足或最终进行截断,也就是出现第一次分块当中的结果。所以说,第一次的分块实际上是一个“妥协”。
递归拆分的过程
- 尝试使用第一个分隔符
\n\n:如果文本长度超过chunk_size,就以\n\n为分隔符拆分文本,以当前文本为例: - 检查拆分后的子文本长度:如果子文本长度仍然超过
chunk_size,就对每个子文本递归地使用下一个分隔符\n进行拆分。 - 检查拆分后的子文本长度(和之前一样):如果子文本长度仍然超过
chunk_size,就对每个子文本递归地使用下一个分隔符chunk 3的“让”字后面有一个空格: - 重复上述过程(如果还有其他分隔符的话):直到使用最小的分隔符
""(即逐字符)进行拆分,这一步将会直接截断:
Reference
- Retrieval Augmented Generation (RAG) for GitLab https://handbook.gitlab.com/handbook/engineering/architecture/design-documents/gitlab_rag/
- RAG: Retrieval Augmented Generation In-Depth with Code Implementation using Langchain, Langchain Agents, LlamaIndex and LangSmith. https://medium.com/@devmallyakarar/rag-retrieval-augmented-generation-in-depth-with-code-implementation-using-langchain-llamaindex-1f77d1ca2d33
- Perplexity https://www.perplexity.ai/