AI Agent Context Engineering
端到端基于开源模型训练反馈很缓慢,不适用与创业公司的节奏。Manus选择押注于基于前沿模型做上下文工程。
将这种手动架构搜索、提示调整和经验猜测的过程称为"Stochastic Graduate Descent"
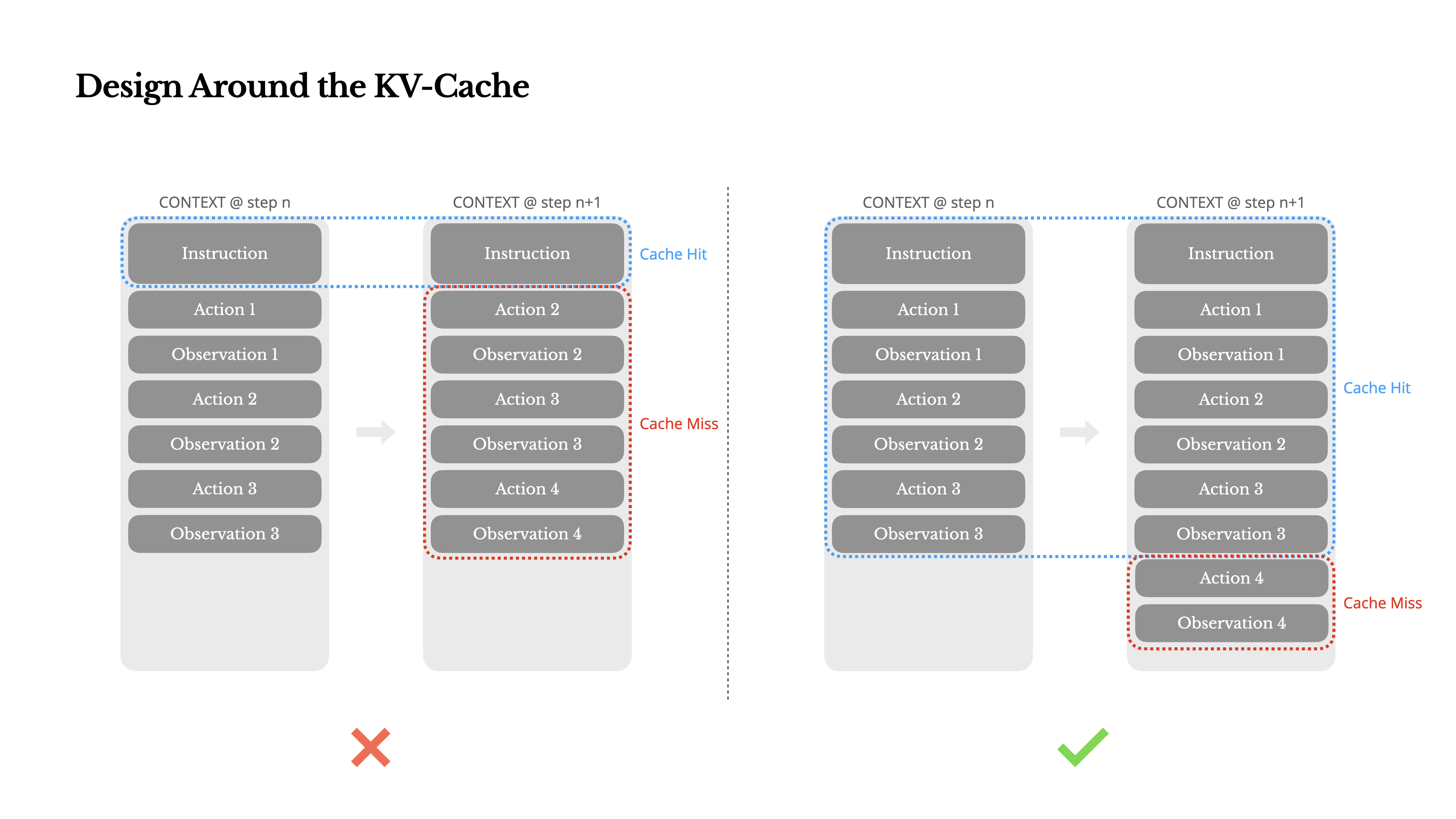
尽可能命中KV-cache
KV-cache的作用
- 决定了首个token的生成时间(TTFT)和推理成本
- 具有相同前缀的上下文可以利用KV缓存
实践中
- 保持prompt前缀稳定
- 使你的上下文只追加。
- 在需要时明确标记缓存断点。在分配这些断点时,要考虑潜在的缓存过期问题,
Mask而不是Remove
在实践中,一个agent会搭载上百个工具(如mcp tool),模型更可能选择错误的行动或采取低效的路径。
Manus尝试过设计一个动态行动空间,动态移除添加tool。结果表明,除非绝对必要,避免在迭代过程中动态添加或移除工具。因为:
- **更改前缀会导致KV-cache失效。**在大多数LLM中,工具定义在序列化后位于上下文的前部,通常在系统提示之前或之后。因此任何更改都会使后续所有动作和观察的KV缓存失效。
- **模型会感到困惑。**当先前的动作和观察仍然引用当前上下文中不再定义的工具时,模型会感到困惑。如果没有约束解码,这通常会导致模式违规或幻觉动作。
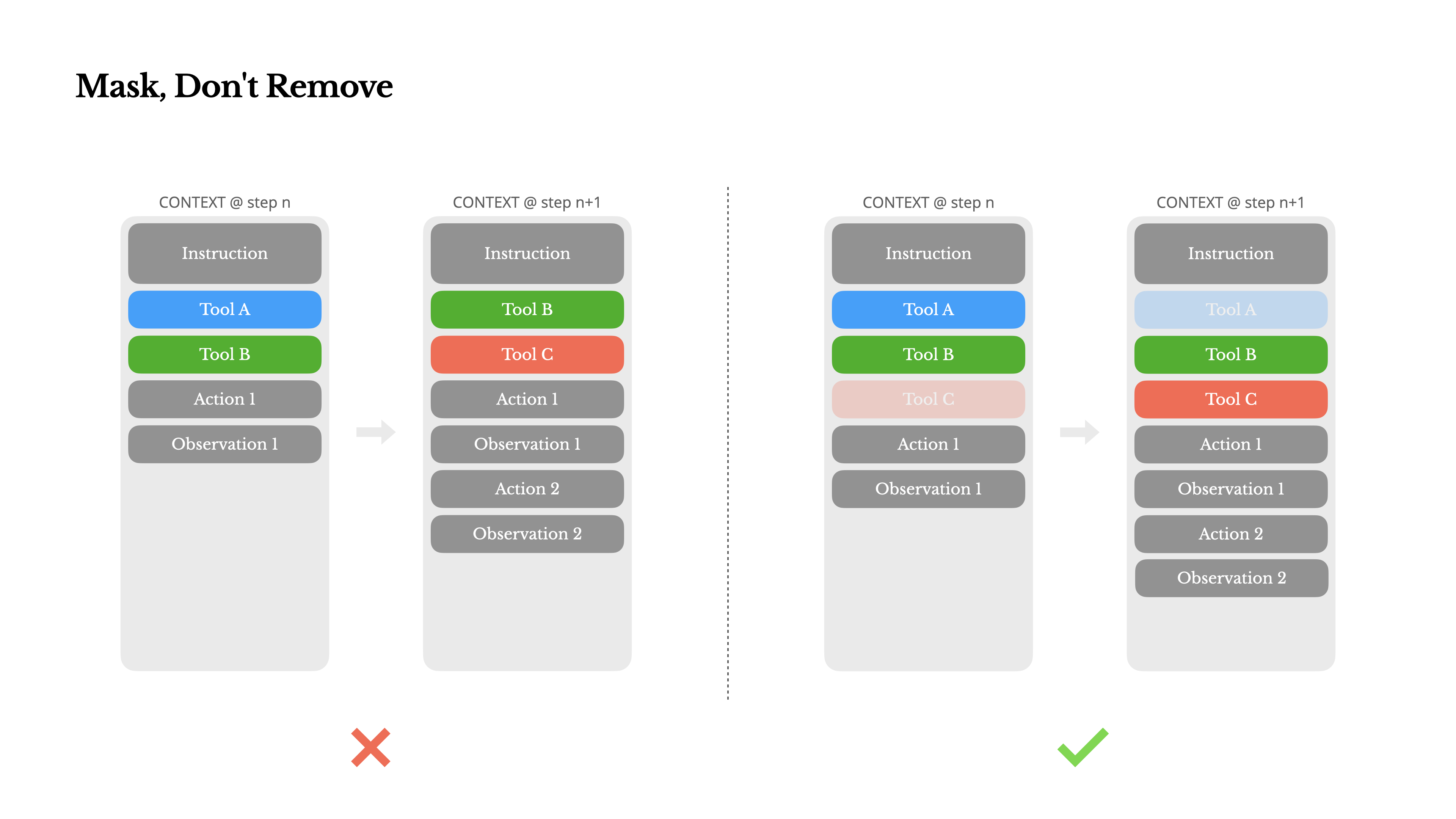
为了解决这个问题并仍然改进动作选择,Manus使用上下文感知的状态机来管理工具可用性。
不是移除tool,而是masks the token logits(掩码token的logits),以基于当前上下文阻止(或强制)选择某些动作。
函数调用通常有三种模式
- 自动 – 模型可以选择调用或不调用函数。通过仅预填充回复前缀实现:
<|im_start|>assistant - 必需 – 模型必须调用函数,但选择不受约束。通过预填充到工具调用令牌实现:
<|im_start|>assistant<tool_call> - 指定 – 模型必须从特定子集中调用函数。通过预填充到函数名称的开头实现:
<|im_start|>assistant<tool_call>{"name": "browser_
所有与浏览器相关的工具都以browser_开头,命令行工具以shell_开头。这使我们能够轻松确保代理在给定状态下只从特定工具组中进行选择而无需使用有状态的logits处理器。
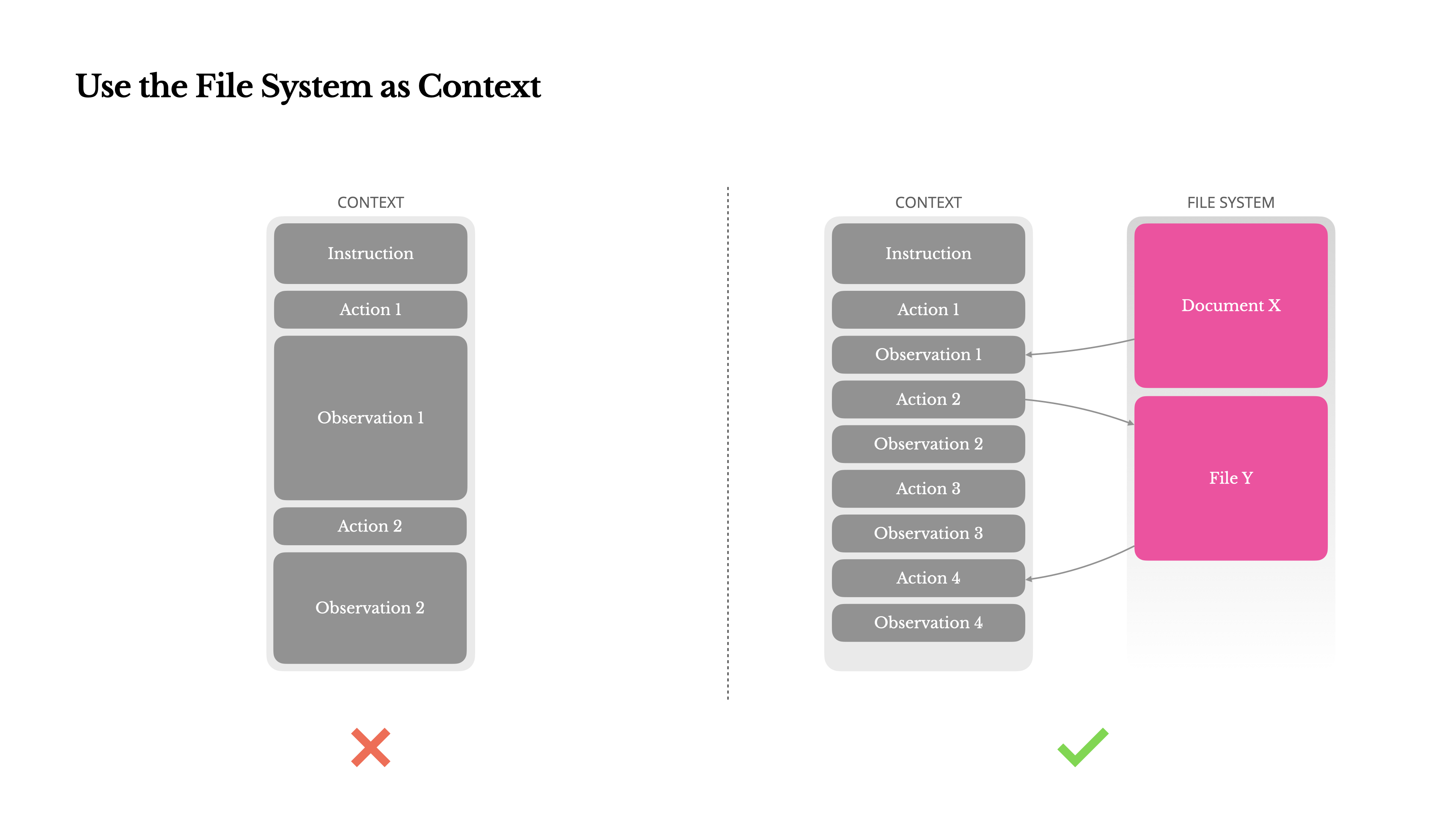
使用文件系统作为上下文
LLM现在提供128K令牌或更多的上下文窗口。但在真实世界的代理场景中,这通常不够,有时甚至是一种负担。
- 观察结果可能非常庞大
- 模型性能往往会下降
- 长输入成本高昂
已有的解决方案为压缩或截断上下文。但过度激进的压缩不可避免地导致信息丢失。
而在文件系统中存储的上下文是持久性的,大小不受限制,并且Agent可以直接操作。
- 只要保留URL,网页内容就可以从上下文中移除;
- 沙盒中仍然保留文档路径,则可以省略文档内容。
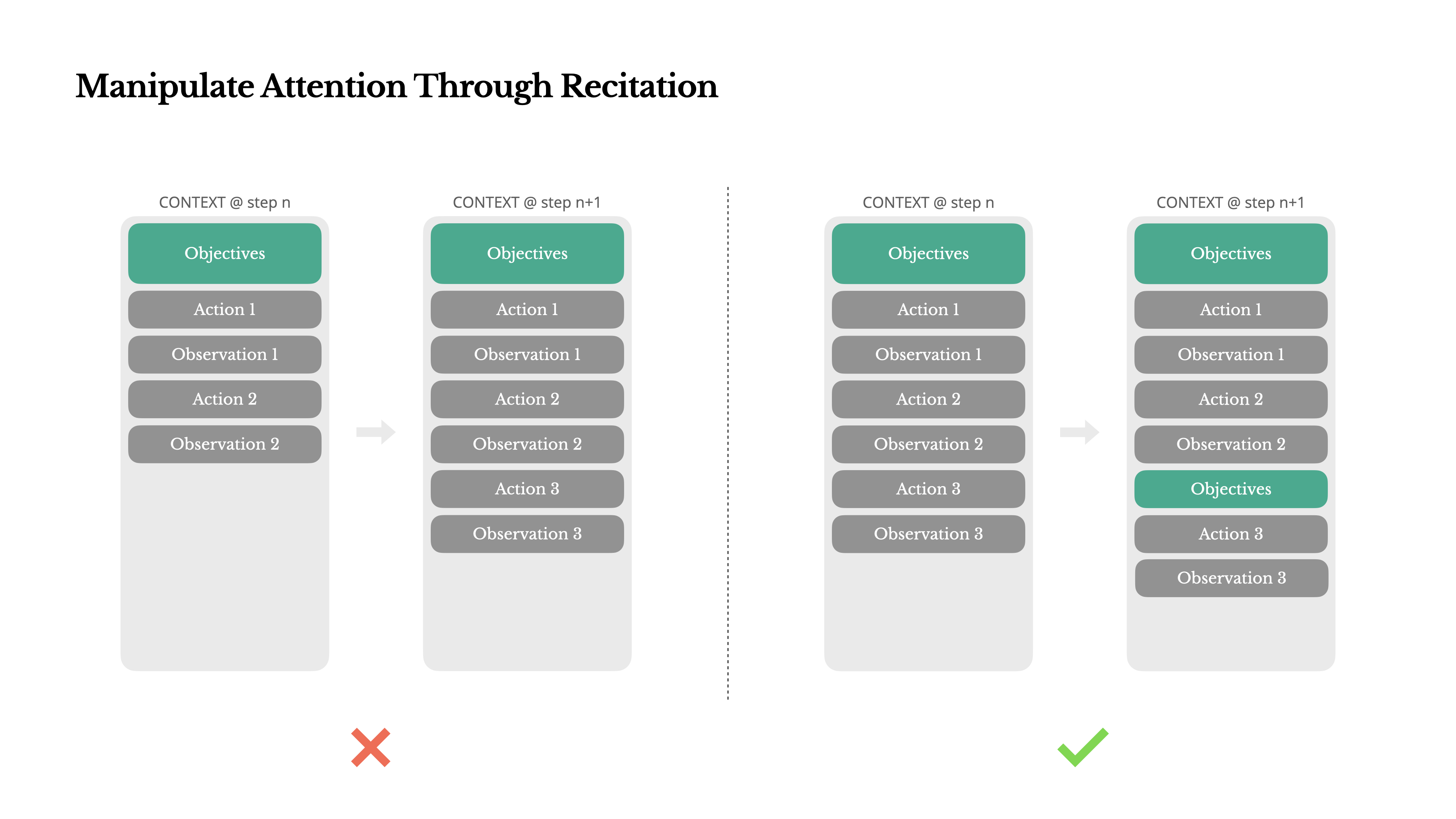
通过复述操控注意力
创建一个todo.md文件——并在任务进行过程中逐步更新它,勾选已经完成的选项。
这是一种操控注意力的刻意机制。 由于Manus依赖LLM进行决策,它很容易偏离主题或忘记早期目标,尤其是在长上下文或复杂任务中。通过不断重写待办事项列表,Manus将其目标复述到上下文的末尾。
这将全局计划推入模型的近期注意力范围内,避免了"丢失在中间"的问题,避免目标不一致。
保留错误的内容
代理会犯错。这不是bug——这是现实。语言模型会产生幻觉,环境会返回错误,外部工具会出现异常行为,意外的边缘情况随时都会出现。
一个常见的冲动是隐藏这些错误:清理痕迹,重试操作,或重置模型的状态并将其留给神奇的"temperature"(黑魔法,更高的动态)。
将错误的尝试保留在上下文中。当模型看到一个失败的行动——以及由此产生的观察结果或堆栈跟踪——它会隐式地更新其内部信念。

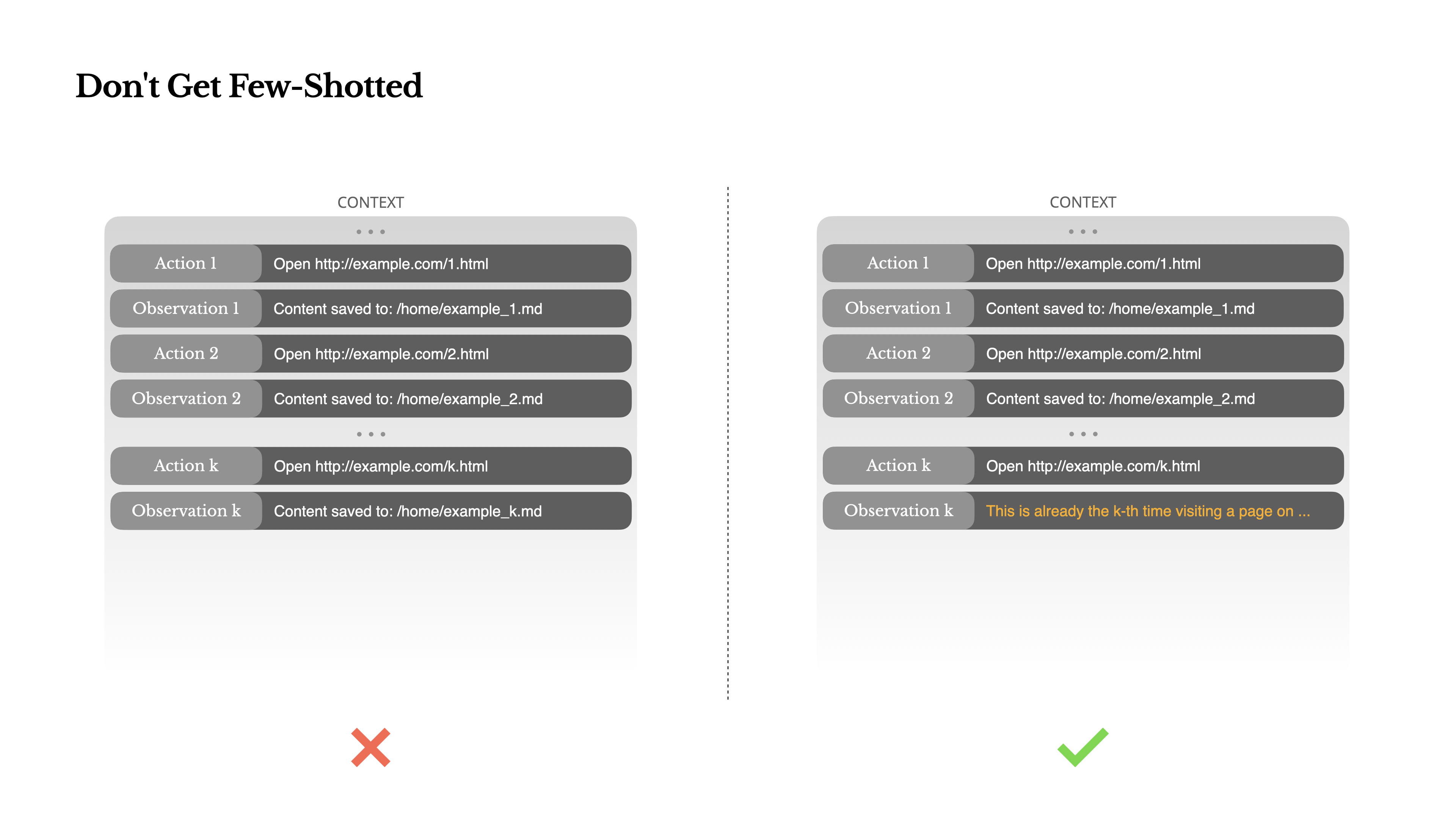
不要被少样本示例所困
Few-shot提示是提高LLM输出的常用技术。但在代理系统中,它可能会以微妙的方式适得其反。 语言模型是优秀的模仿者;它们模仿上下文中的行为模式。
解决方案是增加多样性。Manus在行动和观察中引入少量的结构化变化——不同的序列化模板、替代性措辞、顺序或格式上的微小噪音。这种受控的随机性有助于打破模式并调整模型的注意力。