Lab4 ShardStoreServer
We are not allowed to share codes online.
For more details, Pls refer to NUS CS5223 Lab's Repo: https://github.com/nus-sys/cs5223-labs/tree/main/labs/lab4-shardedstore
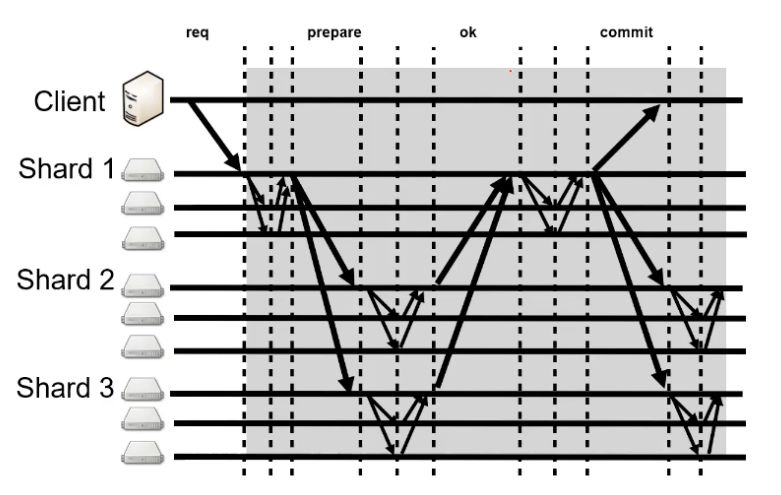
- Shard Master
- 2 phase commit
- Use Paxos to record the decisions
- Distributed Transaction
Part 1 ShardMaster
所以反推join和leave的balance逻辑:
- Join
- totalShardNum / groupNum
==EvenGroupNum - 计算出当前的max和min(差值不超过1)
- 计算需要的remainingShards Number
- shards数量少于EvenGroupNum的group需要补到min
- newGroup需要一个min
- 从多于max的group中拿到多于的shards:RemainingShards
- 如果nonNecessaryShards少于min,把当前拥有max的group尽量一个拆一个,不要小于min了
- 把多于的shards分给
- shards数量少于EvenGroupNum的group
- newGroup
- totalShardNum / groupNum
- leave
- totalShardNum / groupNum
==NewGroupNum - 计算出当前的max和min(差值不超过1)
- 把leave的group的shards拿出来:RemainingShards
- 从多于max的group中拿到多于的shards:RemainingShards
- 把多于的shards分给
- shards数量少于EvenGroupNum的group,都分成至少min
- 再考虑把剩余的平均分给数量为min的group
- totalShardNum / groupNum
演算算法:
Operations
-
Join
-
Req
- groupID
- a set of server addresses
-
Resp
- Process
- should divide the shards as evenly as possible among the groups
- should move as few shards as possible
- Return
- Ok upon Join successfully
- Error if the group already exists
- Process
-
-
Leave
- Req
- groupID(should be a previously joined group)
- Resp
-
Process
- create a new config that doesn't include the group, and assign the group to the remaining groups
- The new configuration should divide the shards as evenly as possible among the groups,
- and should move as few shards as possible to achieve that goal.
-
Return
- Ok upon successful ops
- Error if the group didn't exist
-
- Req
-
Move
-
Req
- shard number
- []GroupID
-
Resp
-
Process
-
create a config in which the shard is assigned to the group
-
the shard is moved from the previous config
-
Return
- OK upon successful completion of Move
- Error otherwise (e.g., if the shard was already assigned to the group).
-
-
Others
- A
JoinorLeavefollowing aMovecould undo aMove, sinceJoinandLeavere-balance. - Purpose: The main purpose of
Moveis to allow us to test your software, but it might also be useful to load balance if some shards are more popular than others or some replica groups are slower than others.
- A
-
-
-
Query
-
Req
- configNum
-
Resp
-
return
shardConfigassociated with the configNum -
if number is
-1or larger than the largest known config number- return the latest config
-
The fist
queryafterJoinis executed- should be numbered by
INITIAL_CONFIG_NUM
- should be numbered by
-
Before the first config is created
- should return
Errorinstead of ashardConfigobject
- should return
-
-
Test Analysis
- Test1
- Join group1(server1, server2, server3) and group2(server4, server5, server6)
- move group2 to the shards of group1
- Expect OK
- leave group2
- Expect OK
- Test2
- query configNum(-1)
- Expect Error because there is no shards
- query configNum(-1)
- test3: Bad commands return ERROR
- join
- repeately
- leave
- a non-joined gorup
- move
- a group to it's existing group
- a non-existing group
- a group to a non-existing sharNum, such as 0 or more than Default_num_shards
- End
- join
- test4: Initial config correct
- check the first initial config num is 0
- and all shards have been assigned to group1
- test5: Basic join/leave
- checkConfig
- what is a balanced config?
- max and min are not null
- max - min
<=1 + (2 * numMoved)<==因为一个move可能会把min移到max上
- Check that groups have the right addresses
- i.e. the group1 have (server1, server2, server3)
- Check mappings are distinct and union to the full shard range
- which is to check each groups are assigned distinct shards. All of the shards should be the full shard range.
- what is a balanced config?
- checkShardMovement
- 遍历previous和current,找到变化的numMoved
- 查看previous和current的group数量差是否小于1
- 如果previous的group数量大于当前group的数量
- 就是leave操作,移除一个group。或者MOVE操作移动group到另一个shard覆盖掉了()
- 找到current缺少的group,判断:
- previous的group的shards等于numMoved
- 如果previous的group数量小于当前group的数量
- 就是join操作了
- 找到current多的group,判断:
- current的这个group的shard number等于numMoved
- 并且查看是否even:totalShardNum / groupNum
==groupNum
- 如果previous的group数量等于当前group的数量
- 就是MOVE操作移动group到另一个shard了,assertEquals(1, numMoved);
- 所以反推join和leave的balance逻辑:
- Join
- totalShardNum / groupNum
==EvenGroupNum - 计算出当前的max和min(差值不超过1)
- 从多于max的group中拿到多于的shards:RemainingShards
- 如果nonNecessaryShards少于min,把当前拥有max的group尽量一个拆一个,不要小于min了
- 把多于的shards分给
- shards数量少于EvenGroupNum的group
- newGroup
- totalShardNum / groupNum
- leave
- totalShardNum / groupNum
==NewGroupNum - 计算出当前的max和min(差值不超过1)
- 把leave的group的shards拿出来:RemainingShards
- 从多于max的group中拿到多于的shards:RemainingShards
- 把多于的shards分给
- shards数量少于EvenGroupNum的group,都分成至少min
- 再考虑把剩余的平均分给数量为min的group
- totalShardNum / groupNum
- end
- Join
- checkConfig
- test6: Historical queries
- query the configs ranges from INT(0) to MAX(5) done in test5
- test7: Move command 1.
- test8
- end
Part 2: Sharded Key/Value Server, Reconfiguration
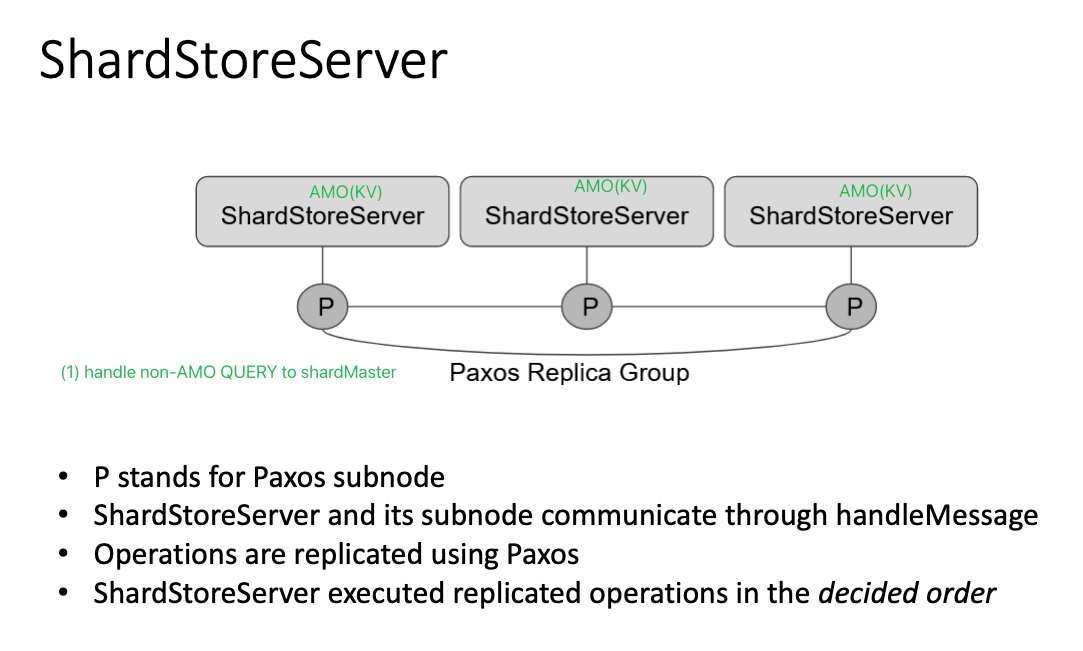
Test Analysis
问题:
-
我们可以只让shardStoreLeader去和Client联系吗?
-
unreliable会阻断client和leader的联系吗?
- 如果是的话,我们需要考虑让follower的store给leader的store发命令吗?
-
会有并发的join、leave、move吗?也就是问会有并发的、密集的reconfig吗?
-
reconfig和普通操作会如何重叠
-
如何知道自己在reconfig需要receive或者send shard?
- 比较一下previous和current的shards
- previous有,current没有的:需要找到下家并send
- previous无,current有的:需要等待receive new shard
-
只要收到ack和receive shark就可以开始proceed了对吗?对
- 因为leader知道了代表整个paxos group都承认了,所以需要把send,receive ack和receive shark都做成一个command,用以保持paxos一致性
-
所以recofing的command有
-
reconfigs prepare,stop processing
needSend = Trueduplicate with 2- needAck = True
- needReceive = True
-
reconfig send
-
reconfig receive shard
-
reconfig receive ack of send
-
-
end
key points
-
just initiate: should get the latest config
-
after which: should get the next config one by one
-
the config should be regard as a AMOcmd
-
send shards should be []KV per move
-
Test1: single group(3 servers inside), shardsMaster(3 servers), client(1), numshards(10)
- join group1
- Simplewordload
-
Test2: Multi-group join/leave
- joinGroup(1, 3);,这里没有用默认值,意思是以后有测试:一个group可以只join一部分server address给shardmaster???
- 一个client,三个store group(3个servers), shardMaster(3 servers), numberShards(10)
- join group1
- put 100 keys
- join group 2 and 3
- wait for 5sec
- check 100 key contents added above
- replace 100 keys values
- leave group 1 and 2
- wait for 5 sec
- check 100 key contents replaced above
-
Test3: Shards move when group joins
- 2 groups of SSS, shardNumber 100
- join group 1
- add 100 key-values
- join group 2, should be evenly, 50 keys on group2
- sleep 5sec
- remove all servers of group1
- query the values of all shards
- the shardsFound should be (1/3, 2/3)
-
Test4: Shards move when moved by ShardMaster
- join group 1
- add 100 key-values
- join group 2, should be evenly, 50 keys on group2
- move
- a series of re-config....
- Move 10 shrads from 1 to group 2 one by one ⭐
- Sleep 5sec
- remove all node in group1
- add a client to each shard for group1 and group2 to get values of key
- sleep 10sec
- invariant:
- client of group2 should compelte operations
- clients of group1 shouldn't complete ops
-
Test5: Progress with majorities in each group
- 每个StoreGroup和shardMasterGroup都只保留Majority ⭐
- Test2: Multi-group join/leave
-
Test6:Repeated partitioning of each group
- join 3 StoreGroup with 3 Servers; numShardMasters = 3, numShards = 10,
- Startup the clients with 10ms inter-request delay (infinite workload)
- Clients with different keys and infinite workload
- // Re-partition -> 2s -> unpartition -> 2s
- Re-partition,即每回合随机禁掉一个StoreGroup的minority,即一个server ⭐
- 等待50s
- 确保每个client的query都在正常工作
- 检查最大等待时间不超过2s
-
Test7:Repeated shard movement
- join 3 StoreGroup with 3 Servers; numShardMasters = 3, numShards = 10,
- Startup the clients with 10ms inter-request delay (infinite workload)
- 不断地随机移动shard,sleep 4s,所以每个move必须4s内完成,期待make progress
- 等待50s
- 确保每个client的query都是线性的
- 检查最大等待时间不超过5s
-
Test8: Multi-group join/leave 【Unreliable】
- network deliver rate 0.8
- Test2: Multi-group join/leave
-
Test9: Repeated shard movement 【Unreliable】
- network deliver rate 0.8
- Test7:Repeated shard movement
-
Test10: Single client, single group 【search test】
- storegroup:1, serverNum: 1, shardMasterNum: 1, shardNum: 10
- client: 1
-
Test11: Single client, multi-group 【search test】
- storegroup:2, serverNum: 1, shardMasterNum: 1, shardNum: 10
- client: 1
-
Test12: Multi-client, multi-group 【search test】
- storegroup:2, serverNum: 1, shardMasterNum: 1, shardNum: 2
- two clients' workload
-
Test13: One server per group random search【search test】
- storegroup:2, serverNum: 1, shardMasterNum: 1, shardNum: 2
- cmd:
- join group1
- Join group2
- leave group1
- Four clients with their workloads
- end
-
Test14: Multiple servers per group random search【search test】
- storegroup:2, serverNum: 3, shardMasterNum: 1, shardNum: 2
- same as Test13
-
end
Part 3: Transactions
Test Cases Analysises
-
被lock挡住的普通amocmd(get,put,append)该怎么办
-
被lock挡住的reconfig怎么办
-
被reject的txn怎么办?
-
需要在接受txnPrepare的时候,直接检查锁并reject嘛?不能!
-
⬆️ 相信奇迹吧
-
怎么样paxos-replicate TxnMsg
-
TODO:在handleMsg和在handlePaxosDecision的时候reject效果是不同的
- 一个是直接就不让paxos判断,一个是经过paxos决定,但是实际却不执行。。。。
- TODO: !!! maybe this drop will cause the client cannot get the response /or cause serializability problem
-
TODO: replicate recieved msg to leader
-
TODO: cancel the isleader() limitation, let follower can forward msg.
-
TODO: but I think the problem is happening during reconfig
-
Test1: Single group, simple transactional workload 1.
-
Test2: Multi-group, simple transactional workload
-
Test3: No progress when groups can't communicate
- Client can talk to both groups, but they can't talk to each other
- So only the txn within a shard is successful, otherwise stuck
-
Test4: Isolation between MultiPuts and MultiGets
- 就是说put的write lock会把get隔绝
-
🆕
-
Test5: Repeated MultiPuts and MultiGets, different keys
- repeatedPutsGetsInternal() => doesn't including movement
-
Test6: Repeated MultiPuts and MultiGets, different keys 【unreliable】
- networkDeliverRate(0.8)
- repeatedPutsGetsInternal() => doesn't including movement
-
Test7: Repeated MultiPuts and MultiGets, different keys; constant movement 【unreliable】
- networkDeliverRate(0.8)
- repeatedPutsGetsInternal() => including movement
-
Test8: Single client, single group; MultiPut, MultiGet 【Serach】
-
Test9: Single client, multi-group; MultiPut, MultiGet 【Serach】
-
Test10: Multi-client, multi-group; MultiPut, Swap, MultiGet 【Serach】
-
Test11: One server per group random search 【Serach】
- randomSearch
- client1 multiPut("foo-1", "X", "foo-2", "Y")
- Client2 multiGet("foo-1", "foo-2")
- 要么没有结果,要么结果全为空、要么结果为(X,Y)
-
Test12: Multiple servers per group random search 【Serach】
-
End