分布式状态,如何定义一致性? Distributed State and Consistency
Why Distributed State?
One way of characterizing computation is as a set of operations applied to an initial state in order to produce some (presumably more interesting) fifinal state. In this interpretation, programming is the act of invoking and organizing state transitions.
-- The Role of Distributed State
Take distributed file system as an example, we may need to cache file conent for performance and reducing the overhead.
- Client cache the file content locally
- Server cache the file content in memory, so that it doesn't need to read them from disk which takes lots of time.
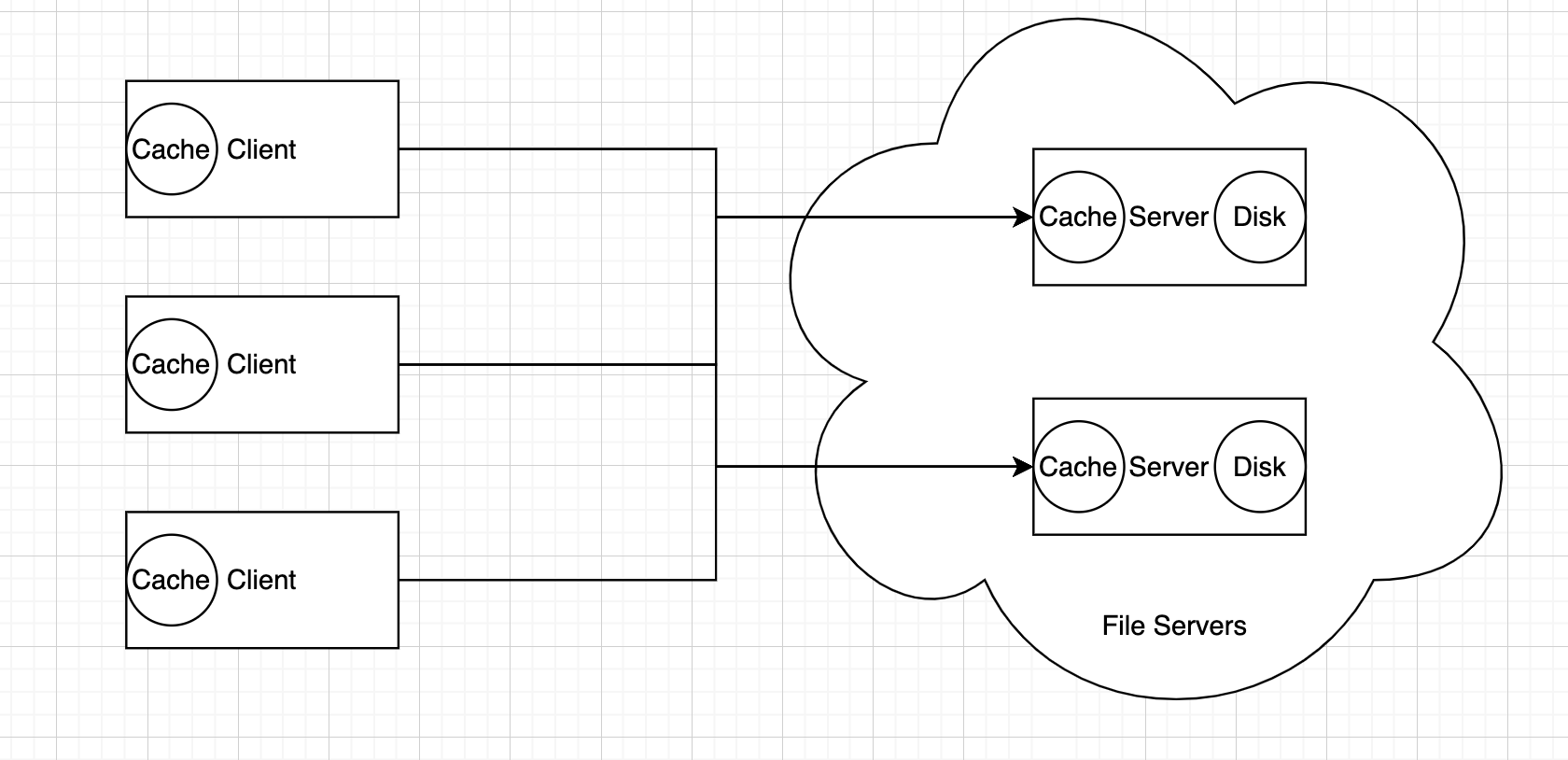
Cache
- Exploit locality. Reduce load on bottleneck service.
- Batter Latency
- Move the data to where it is used. So RPC is moving the computation to where the data is.
But cache may cause inconsistent distributed state.
Let's talk about two typical file system design.
- NFS
- Sprite
NFS File System
Developed by Sun Microsystems in 1984
Design philosophy: simplicity
Stateless
- The file is only in the server's disk. Can still cache data in servers' memory, but they are unreliable and can not depend on them.
- Servers do not cache client's info as well.
Idempotent operations
- Write and read at offset
- Lookup
When client updates file
- Updates file cache locally
- Sends wirte request to server
- Server writes data to disks
Performance
- Performance is bad because all updates go through the server's disk
Consistency
- The client will periodically poll the file content from servers. Eventually reach a consistent state.
Sprite File System
Sprite: Unix-like distributed OS from Berkeley
Track the file open/close status
Use write-back cache (the other term is write through)
- Store the modified block in cache first
- Writes back to disk after 30s
Update Protocol
- Only one client opens the file
- Synchronously update
- Flush after 30s
- Multiple clients open the file
- Read/write thorugh the servers (no clients can cache the files)
Pros and cons
- Pros:
- Consistency
- Performance
- Cons
- Complexity
- Durability and Disaster recovery
- Sprite can ensure Concurrent and Sequential Write-Sharing but cannot resolve the crash recovery. Say there is one client updates the file. Within 30s, the modification blocks are not yet updated to disk before the server crash. Then Sprite cannot ensure linearizability. (The modification is kept in volatile memory so it will disappear after system crashs).
- Trade-offs
Distributed State
Distributed State: Information retained in one place that describes something, or is determined by something, somewhere else in the system.
Example of distributed state:
- A small table kept on each host to associate network addresses with the textual names of other hosts.
Benefits
- Performance
- Reliability
- Coherence
A new problem occurs while introducing a distributed state
How to ensure/maintain the consistency of distributed state. Take the caching file as an example, the data in multiple machines should be updated consistenly, otherwise different client will read different file content.
Consistency
Why do we need formal Definition of consistency?
- We need to define what's the latest data, whether we can see the stale data. Whether we really need to read the latest data.
- If there are multiple clients write or read simultaneously, what is the consistency, which one should client read?
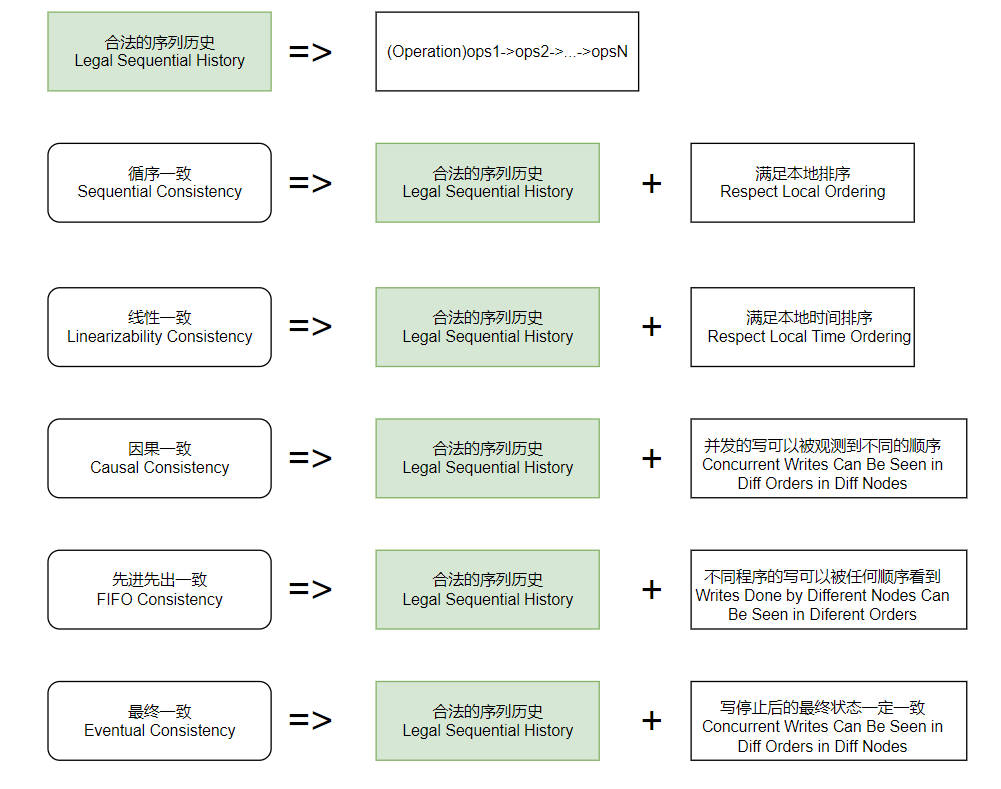
Serializability Consistency
Requires that the history of operations be equivalent to a legal sequential history, where a legal sequntial history is one that respects the local ordering at each node.
- Legal history sequence
- Respect local event order
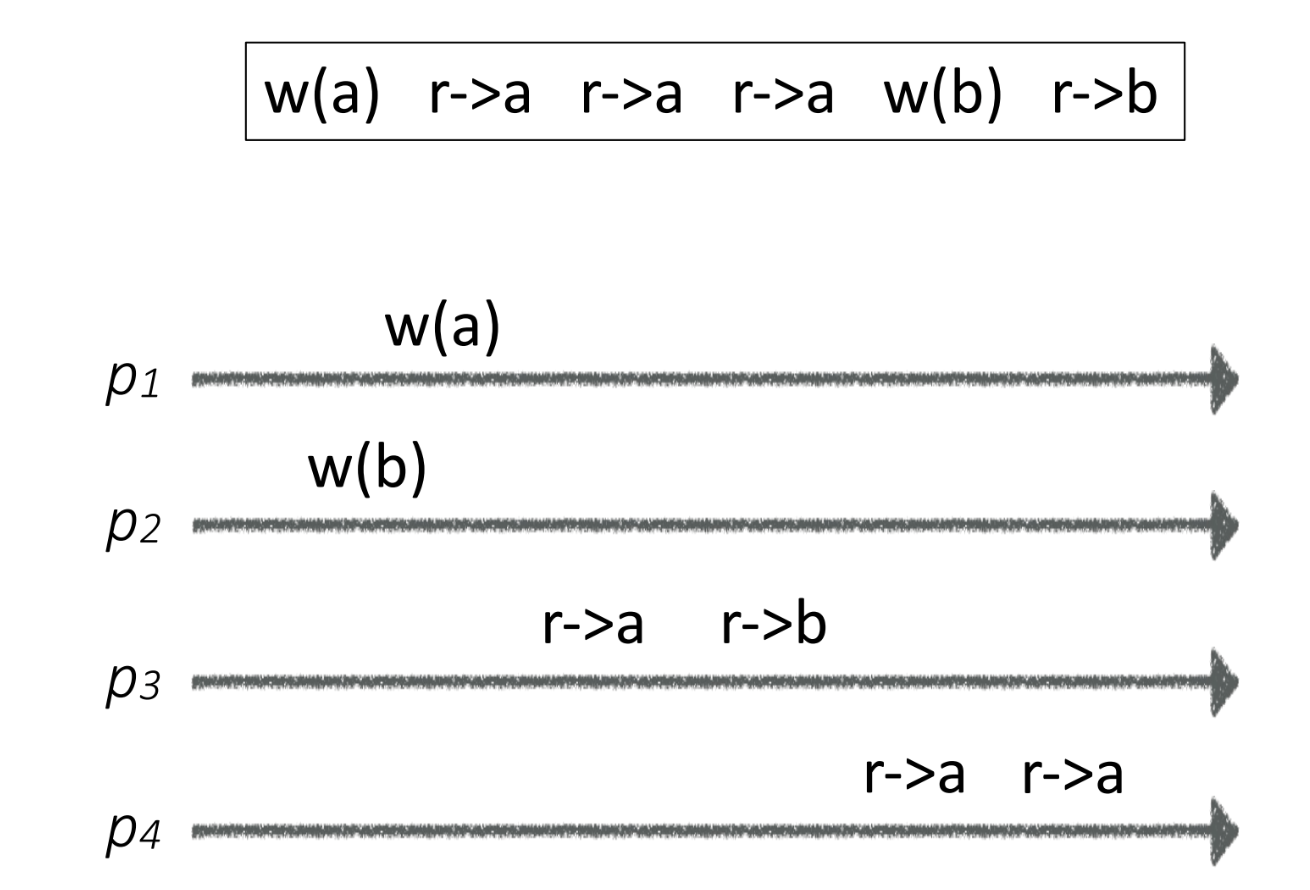
Linearizability Consistency
One of the strongest guarantees for concurrent objects.
- Legal history sequence
- Respect local event order in real time
Serializability in database is similar to linearizability. It emphasizes that the execution result of txns are like running them serializably, i.e. one by one, even if they are actually executed concurrently.
Consistency
- Causal Consistency
- Writes that are not concurrent (i.e., writes related by the happens before relation) must be seen in that order. Concurrent writes can be seen in different orders on different nodes.
- Lineariziblity implies Causal consistency
- Sometimes the a sequence is causal but not sequential.
- FIFO Consistency:
- writes done by the same process are seen in that order; writes by different processes can be seen in different orders.
- Eventual Consistency: if all writes to an object stop, eventually all processes read the same value.
CAP and BASE theorem
CAP
- Consistency
- Availability
- Partition Tolerance
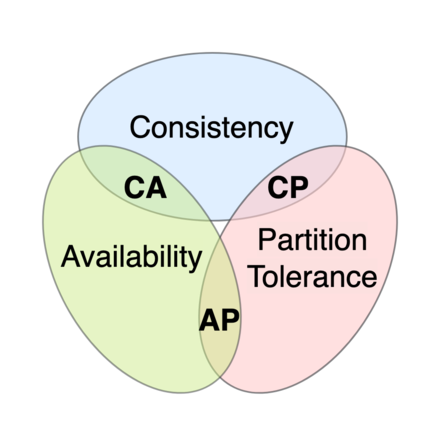
In database theory, the CAP theorem, also named Brewer's theorem after computer scientist Eric Brewer, states that any distributed data store can provide only two of the following three guarantees
These CAP properties cannot be achieved at the same time.
BASE
- Basically Available
- Soft State
- Eventually Consistent
BASE theorem is the result of the trade-off between consistency and availability in CAP. Its core idea is: if strong consistency cannot be achieved, each system can adopt their approaches to make the system achieve eventual consistency.
Reference
- NUS CS5223 Distributed System Course
- Distributed State by John K. Ousterhou
- Distributed System