[System Design] AI Chatbot
Requirement
Functional Requirement
- Chat
- Persistent Chat History
- Biz Knowledge Chat
- Multiple Chat Window
- Natural Language Understanding and Reply
- Features
- Task Detection
- Tool
- Long/short term user behavior memory
- Web Search
Non-Functional Requirement
- Scalability
- 100M Users
- (More?)
- High Availability
- 99.99% SLA
- Low Latency
<1s response latency
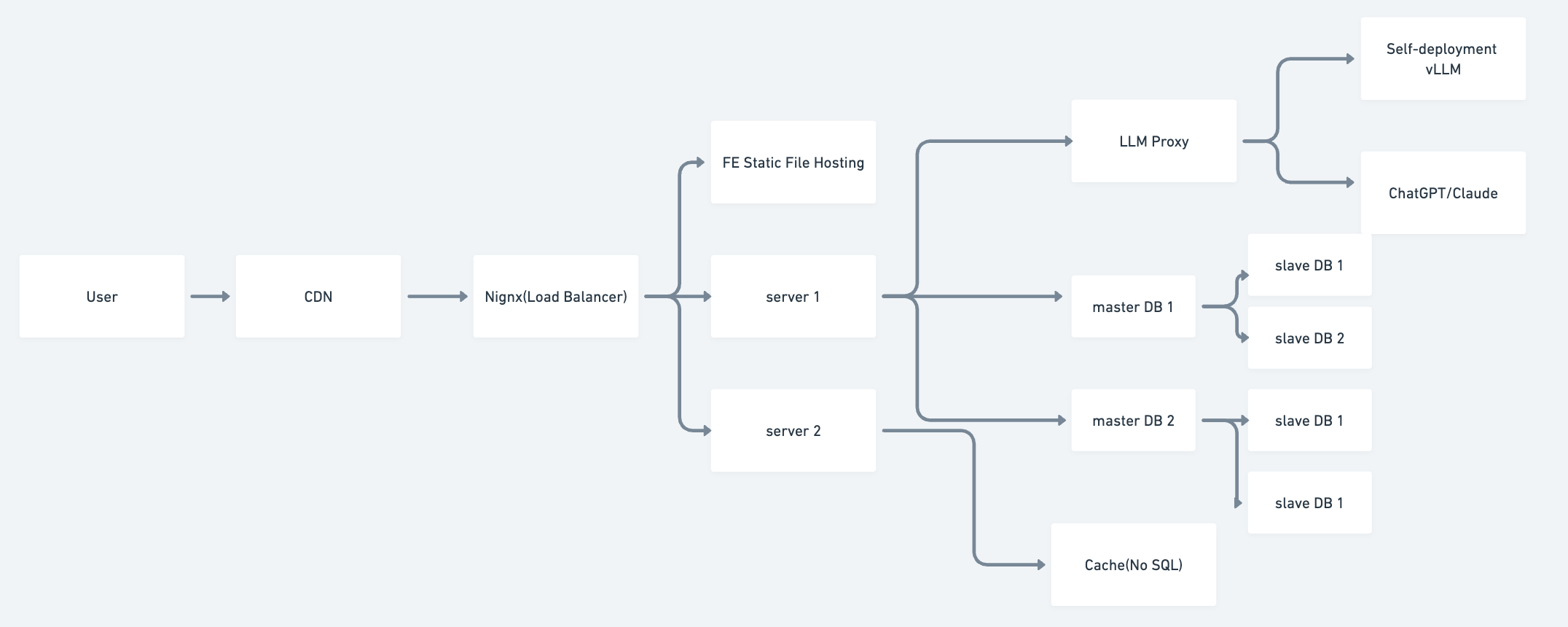
Architecture
- Singleton Service
- Backend Frontend Separate
- Microservice
Feature Implementation
- Single Chat
- Persistent Chat History ⇒ RDB/No SQL/Object Storage(Multi-media storage)
- Biz Knowledge Chat ⇒ (RAG, retrieval augmented generation)
- Natural Language Understanding and Reply ⇒ (Rule Based NLP ⇒ LLM)
- Features
- Task Detection ⇒ LLM
- Tool ⇒ MCP? LLM Tool/Function Calling
- Long/short term user behavior memory ⇒ DB
- Web Search ⇒ web search tool
Persistent Chat History
Table Design
chat_tab {
chat_id uint64 primary_key,
user_id uint64 index,
title char(16),
c_time uint64,
m_time uint64
}
message_tab {
message_id uint64 primary_key,
chat_id uint64 index,
user_id uint64,
content text(~10,000),
c_time uint64,
m_time uint64
}
Storage
one chat, 10 messages(5 users, 5 bots, avg content length 500bytes)
50 bytes + 600 bytes * 10 ~= 6000 bytes ⇒ 10KB
100M users, 20% DAU, 10 chat a day
100M * 10 * 10KB * 20% = 2TB
365 * 2TB = 730 TB / year
db sharding
chat_tab by user_id
message_tab by chat_id
db partitioning
by user_id?
Chat
API interface
/api/v1/chat
request_body {
user_id,
chat_id(optional),
messages,
stream
}
respone_body {
chat_id
messages,
}
connection type
- HTTP polling
- HTTP long polling(one HTTP longactive connection
- Websocket
QPS
one chat, 10 messages
100M users, 20% DAU, 10 chat a day
avg QPS
100M * 20 % * 10 * 5 /86400 = 1B /100k = 10K/sec
peak(5 times)
50k/sec
latency
- 200ms server-client latency
- 100ms server processing
- 600ms LLM ttft(time to first token)
High Availability
- load balancer
- cache
Trade-off
Large model VS Small model
- Cost VS Accuracy/Inference
API provider VS Local deployment
- Cost VS Latency/Efficiency